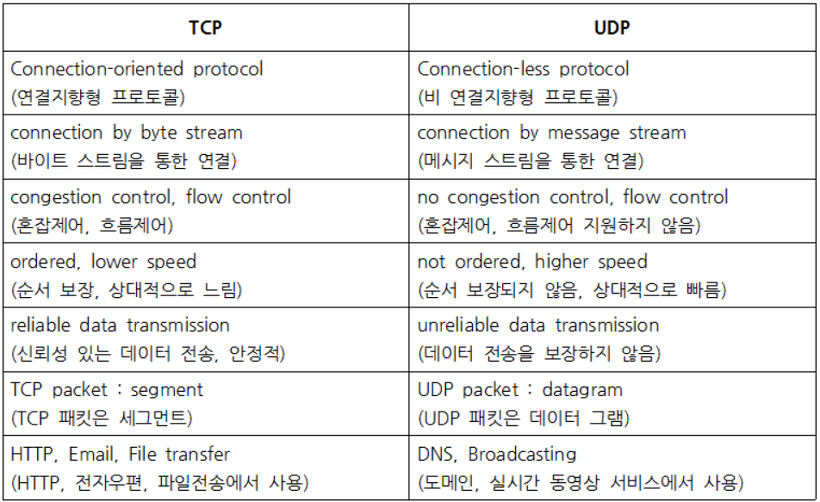
가비지 컬렉션
쉽게 이야기해서 Java가 개발자 대신 사용하지 않는 객체를 자동으로 찾아 메모리에서 제거해줌으로써 메모리를 관리해주는 것이다.
GC 대상이 되는 객체
- 모든 객체 참조가 null 인 경우
- 객체가 블럭 안에서 생성되고 블럭이 종료된 경우
- 부모 객체가 null이 된 경우, 자식 객체는 자동적으로 GC 대상이 된다.
- 객체가 Weak 참조만 가지고 있을 경우
- 객체가 Soft 참조이지만 메모리 부족이 발생한 경우
가비지 컬렉션 과정 - Generational Garbage Collection
Generational Garbage Collection에서는 힙을 Young, Old or Tenured, Permanent Generation으로 나눈다.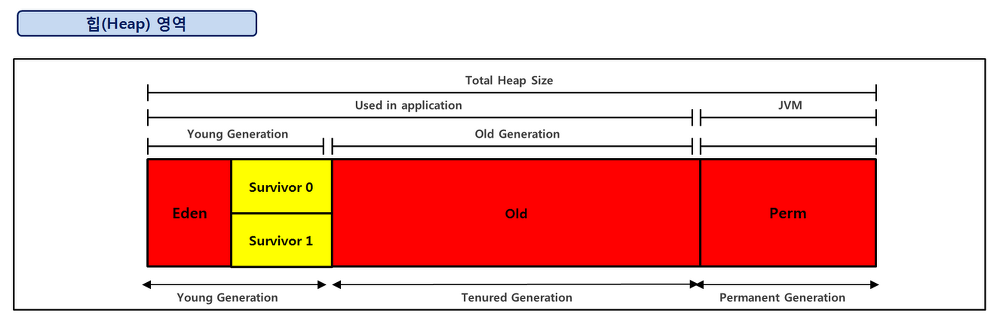
Young 영역
- 새롭게 생성한 객체의 대부분이 여기에 위치한다.
- 가득차게 되면 minor garbage collection이 일어난다.
- 대부분 객체가 금방 사라지기 때문에 많은 객체가 이 곳에서 사라진다.
Old 영역
- 접근 불가능 상태가 되지 않고 Young 영역에서 살아남은 객체들이 복사된다.
- Young 영역 보다 크기가 크게 할당하고 큰 만큼 GC는 적게 발생한다.
- 이 영역에서 객체가 사라질때 Major GC라고 한다.
Permanet 영역
- Method Area라고도 한다.
- JVM이 클래스들과 메소드들을 설명하기 위해 필요한 메타데이터들을 포함하고 있다.
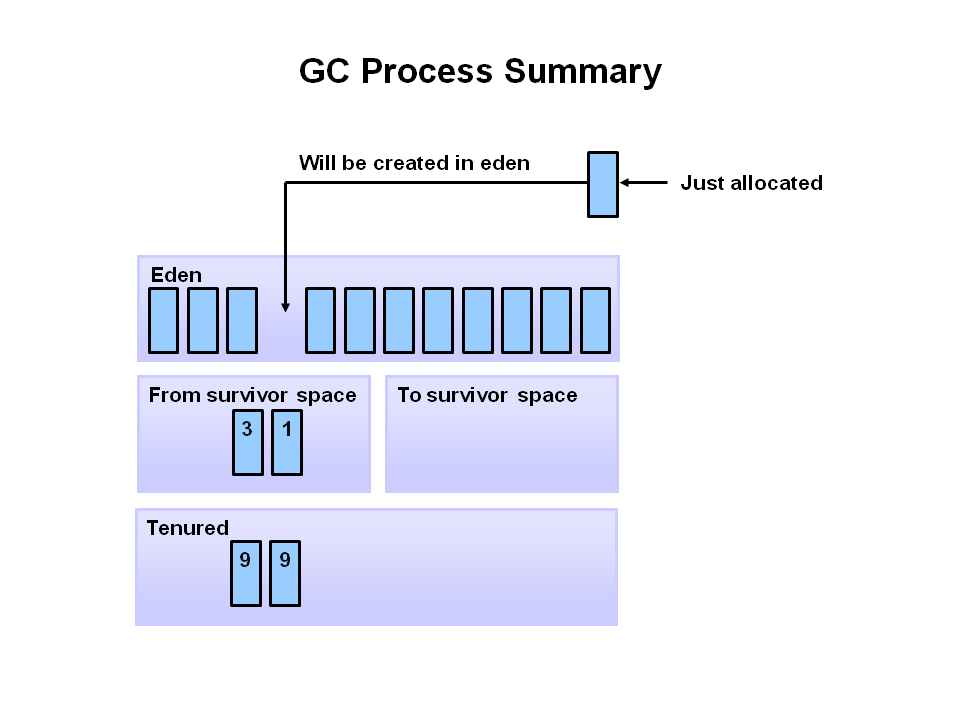
- 새로운 객체는 Eden space에 할당 된다.
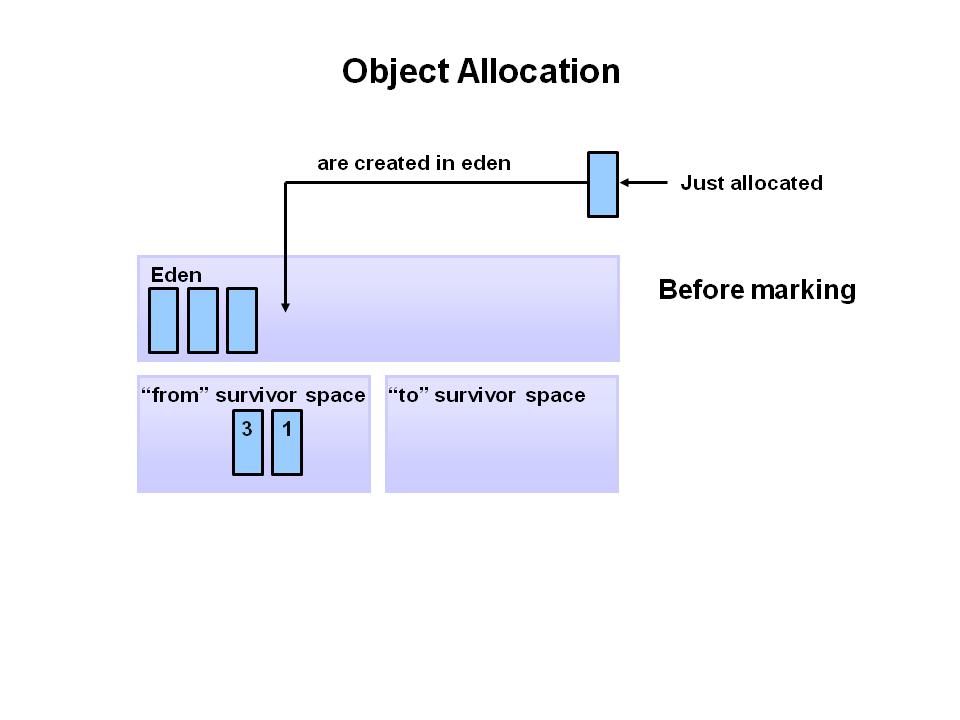
- Eden space가 채워지면 minor garbage collection이 시작 된다.
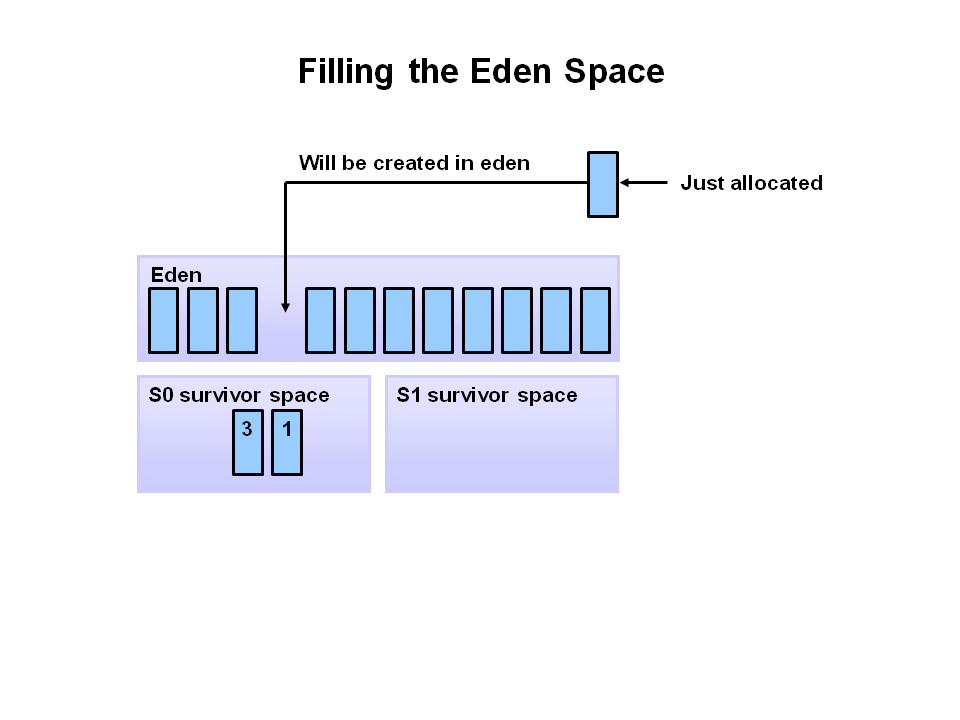
- 참조되는 오브젝트들은 첫 번째 S0로 이동되어지고, 비 참조 객체는 Eden space가 clear 될 때 반환된다.
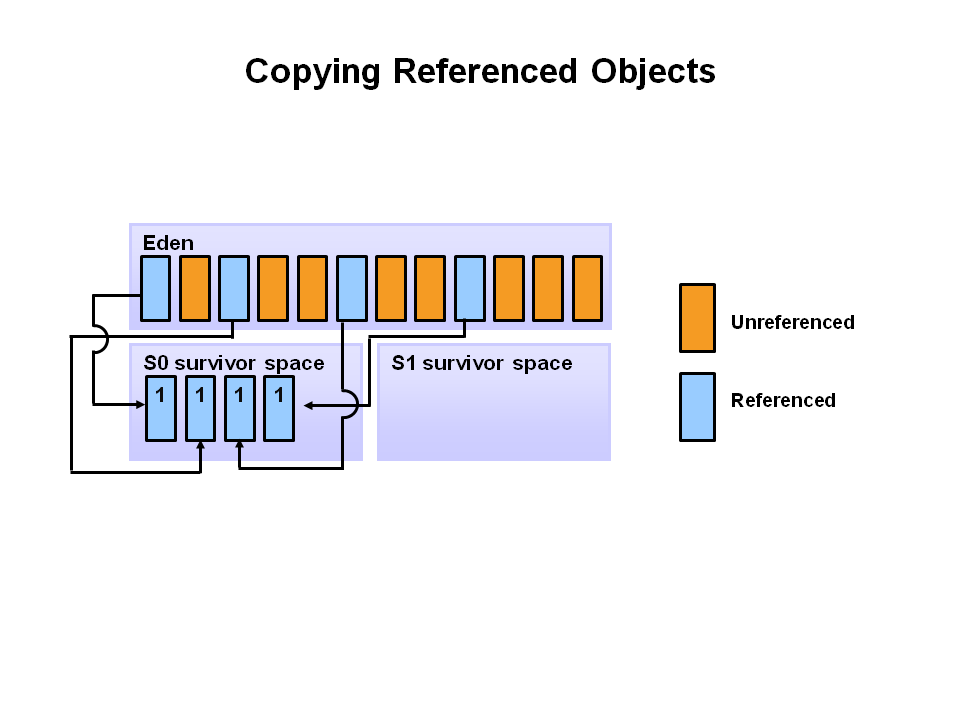
다음 minor garbage collection이 시작될때 Eden space에서 비 참조 객체는 삭제되고 참조객체는 참조 객체는 두번째 S1로 이동한다.
또한 S0의 minor minor garbage collection를 통해 S1공간으로 이동하게 되며 age가 증가 된다.
모든 객체들이 S1으로 이동하게 되면 S0와 Eden space는 Clear 된다.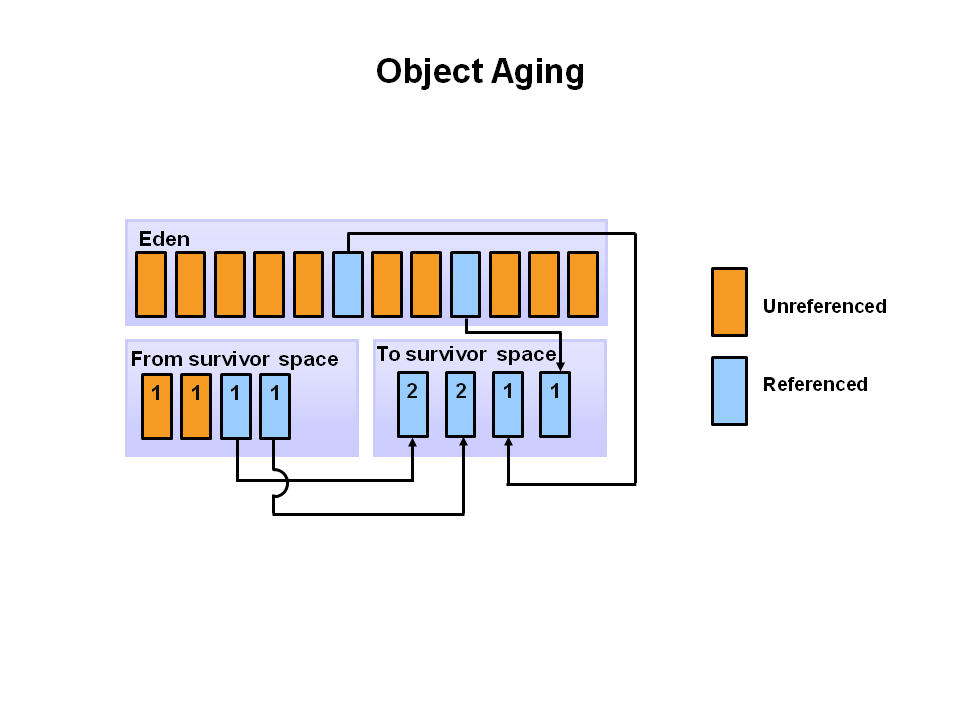
다음 minor garbage collection에도 S0로 같은 작업이 반복된다. 그리고 Eden Space와 S1 공간은 Clear 된다.
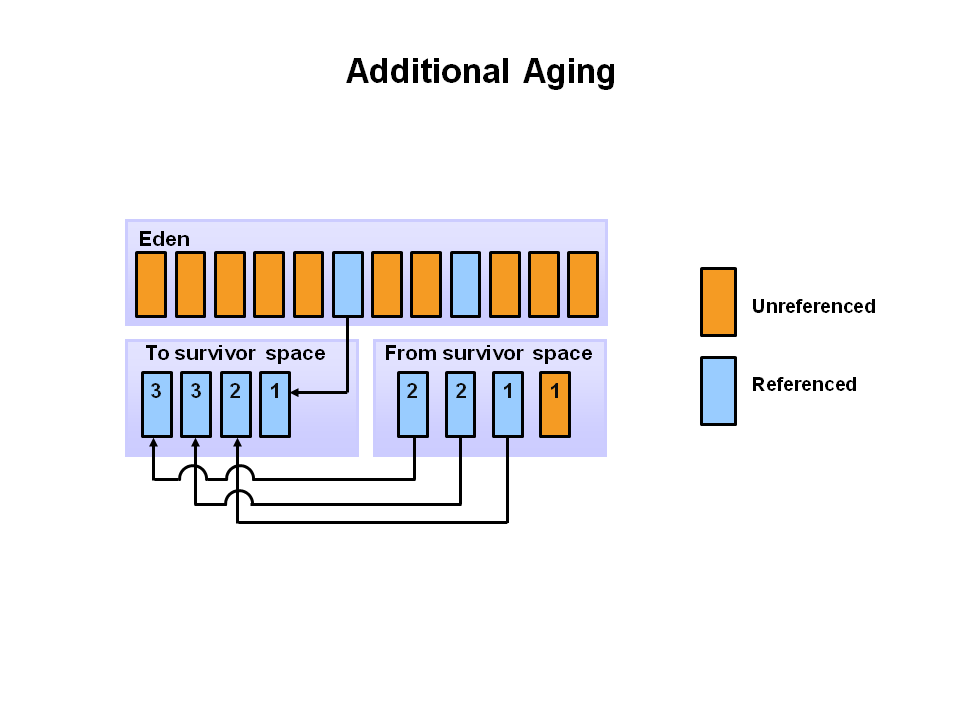
- minor garbage collection 후 일정한 age를 넘게 되면 young generation에서 old로 승격 된다.
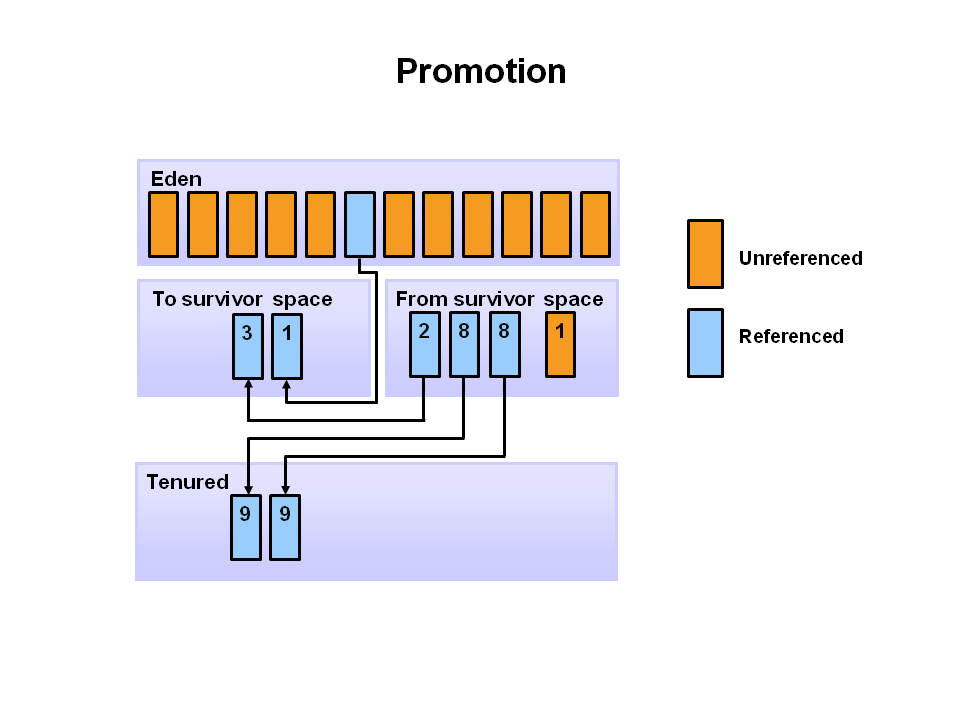
- minor garbage collection가 계속 발생하면 객체는 게속 old로 승격된다.
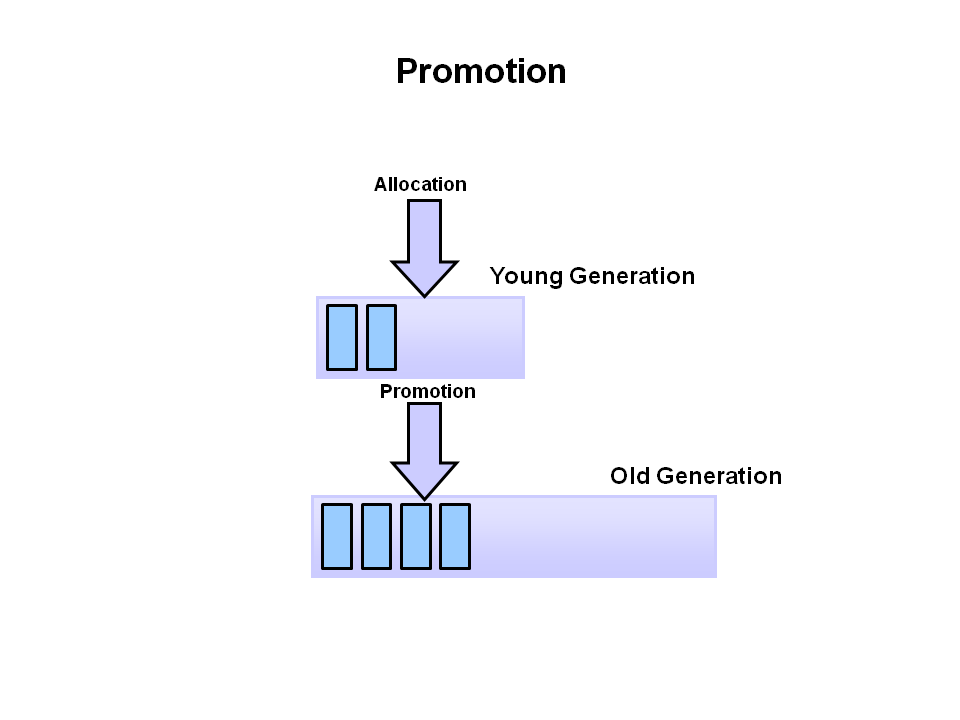
- 결국 major garbage collection가 일어나며 old가 Clear 되고 정리된다.